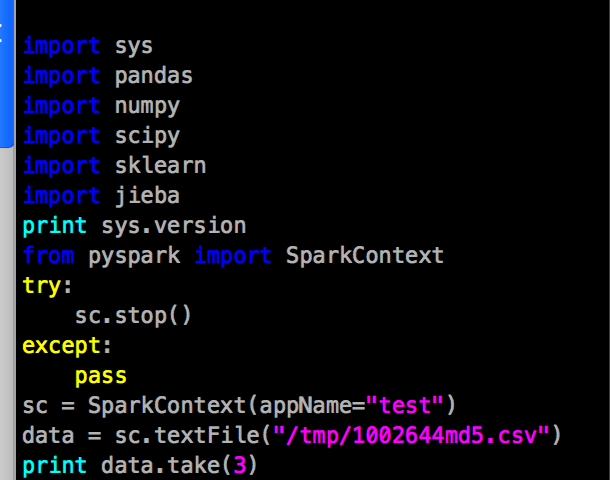
As we use CDH 5.14.0 on our hadoop cluster, the highest spark version to be support is 2.1.3, so this blog is to record the procedure of how I install pyspark-2.1.3 and integrate it with jupyter-lab.
Evironment:
spark 2.1.3
CDH 5.14.0 – hive 1.1.0
Anaconda3 – python 3.6.8
- Add export to spark-env.sh
export PYSPARK_PYTHON=/opt/anaconda3/bin/python export PYSPARK_DRIVER_PYTHON=/opt/anaconda3/bin/jupyter-lab export PYSPARK_DRIVER_PYTHON_OPTS=' --ip=172.16.191.30 --port=8890'
- install sparkmagic
pip install sparkmagic
- Use conda or pip command to downgrade ipykernel to 4.9.0, cause ipykernel 5.x doesn’t support sparkmagic, it will throw a Future exception.
https://github.com/jupyter-incubator/sparkmagic/issues/492 - /opt/spark-2.1.3/bin/pyspark –master yarn
If you need to run with backgrand , use nohup.
if nessasery, add a kernel json at /usr/share/jupyter/kernels/pyspark2 or /usr/local/share/jupyter/kernels/pyspark2, with the content as
{
"argv": [
"python3.6",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"display_name": "Python3.6+PySpark2.1",
"language": "python",
"env": {
"PYSPARK_PYTHON": "/opt/anaconda3/bin/python",
"SPARK_HOME": "/opt/spark-2.1.3-bin-hadoop2.6",
"HADOOP_CONF_DIR": "/etc/hadoop/conf",
"HADOOP_CLIENT_OPTS": "-Xmx2147483648 -XX:MaxPermSize=512M -Djava.net.preferIPv4Stack=true",
"PYTHONPATH": "/opt/spark-2.1.3-bin-hadoop2.6/python/lib/py4j-0.10.7-src.zip:/opt/spark-2.1.3-bin-hadoop2.6/python/",
"PYTHONSTARTUP": "/opt/spark-2.1.3-bin-hadoop2.6/python/pyspark/shell.py",
"PYSPARK_SUBMIT_ARGS": " --jars /opt/spark-2.1.3-bin-hadoop2.6/jars/greenplum-spark_2.11-1.6.2.jar --master yarn --deploy-mode client --name JuPysparkHub pyspark-shell",
"JAVA_HOME": "/opt/jdk1.8.0_141"
}
}
Another problem, in pyspark, sqlContext cannot access remote hivemetastore and without any exceptions, when i run show databases in pyspark, it always return me default. And then i found out, in spark2’s jars dir, there was a hive-exec-1.1.0-cdh5.14.0.jar, delete this jar file, everythings ok.