Python is useful for data scientists, especially with pyspark, but it’s a big problem to sysadmins, they will install python 2.7+ and spark and numpy,scipy,sklearn,pandas on each node, well, because Cloudera said that. Wow, imaging this, You have a cluster with 1000+ nodes or even 5000+ nodes, although you are good at DevOPS tools such as puppet, fabric, this work still cost lot of time.
Why do we have to install python on each node? Because on cluster mode, your py script will be contained to a jar archive through py4j and SparkContext and distributed to every node they will be run. So you must ensure that these nodes have python and spark explaination environment, it means you must install numpy, sklearn… these packages on these node at least. But, these python packages doesn’t support Python 2.6 anymore, so your sysadmin must compile Python 2.7 and then pip install these packages on each node with legacy system such as CentOS 6.x .
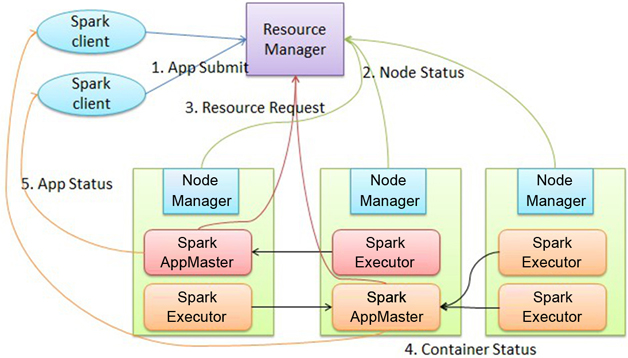
So, I don’t want to do this terrible work, then I found another express way to run pyspark + sklearn + numpy + other machine learning libraries on YARN and without install these libraries on every node. Only I did is installed a hadoop+pyspark+sklearn client. It can submit pyspark+sklearn job to the cluster which did not installed any python environment. Let’s see my code.
#/usr/local/python/bin/python
import math
import sys
import urllib
import re
from collections import namedtuple
import random
from math import sin, cos, sqrt, atan2, radians
import json
from pyspark import SparkContext
try:
sc.stop()
except:
pass
import pandas as pd, numpy as np
from sklearn.cluster import DBSCAN
sc = SparkContext(appName="machine_learning")
def get_device_id(idfa,idfa_md5,imei):
device_id=''
if idfa !='' and re.search(r'[a-zA-Z0-9]{8}-[a-zA-Z0-9]{4}-[a-zA-Z0-9]{4}-[a-zA-Z0-9]{4}-[a-zA-Z0-9]{12}',idfa) != None:
device_id=idfa
elif idfa_md5 !='' and re.search(r'[a-zA-Z0-9]{32}',idfa_md5) != None:
device_id=idfa_md5
elif imei !='' and re.search(r'0-9]{15}|[a-zA-Z0-9]{32}',imei) != None:
device_id=imei
return device_id
def get_xyz(loc):
ll = re.split("x|\*",loc)
try:
xy = tuple(ll)[0:2]
xy = (float(xy[0]),float(xy[1]))
return xy
except:
return(-1,-1)
def dbscan_latlng(lat_lngs,mim_distance_km,min_points=10):
coords = np.asmatrix(lat_lngs)
kms_per_radian = 6371.0088
epsilon = mim_distance_km/ kms_per_radian
db = DBSCAN(eps=epsilon, min_samples=min_points, algorithm='ball_tree', metric='haversine').fit(np.radians(coords))
cluster_labels = db.labels_
num_clusters = len(set(cluster_labels))
# clusters = pd.Series([coords[cluster_labels == n] for n in range(num_clusters)])
# print('Number of clusters: {}'.format(num_clusters))
return cluster_labels
table_file='/user/hive/warehouse/temp.db/id_lat_lng_201704/00018*'
lbs = (sc
.textFile(table_file,5000)
.map(lambda a: a.split("\x01"))
.map(lambda a: (get_device_id(a[3],a[4],a[5]),get_xyz(a[6]))) #[ip,day,hour, id ,(lat,lng)]
.filter(lambda (id,(lat,lng)): lat != -1 and lat !=0.0 and id !='' and id !='00000000-0000-0000-0000-000000000000')
.map(lambda (id,(lat,lng)) : (id,[(lat,lng)]))
.reduceByKey(lambda a,b : a +b )
.filter(lambda (id, lbss): len(lbss) > 10 )
)
lbs_c = lbs.map(lambda (id, lat_lngs):(id, dbscan_latlng(lat_lngs,0.02,1) ))
print lbs_c.count()
This code uses sklearn, pyspark, pandas to calculate lbs geo count num. I run this code in a cluster without python environment successfully.
The step below:
- You must have a client node that can access hdfs and yarn cluster, with spark-core and spark-python installed on it. set $SPARK_HOME and join it to $PATH
- Compile Python 2.7.13 with shared lib to /usr/local/python and install easy_install or pip
- pip install numpy scipy pandas sklearn jieba sparkly pyinstaller
- Go to /usr/lib/spark/python/lib, find py4j-0.x-src.zip and pyspark.zip, unzip them and install them into /usr/local/python/lib/python2.7/site-packages
- This is the final step: use pyinstall to compile your code, and just run it.
pyinstaller -F machine_learning.py
and if you use skearn maybe you should add –hidden-import sklearn.neighbors.typedefs or other hidden import classes. - cd dist/ && ./machine_learning
- Enjoy your result.
In this example, pyinstaller -F will compile all python environment with all needed libraries and you code into one executable file, so with this file runs ,it will call pyspark, pyspark will call spark and submit this job to yarn, yarn will distribute this single file to hadoop’s distributed cache, and with this single file contains all needed python interpreter and numpy, sklearn… these libraries, it should be run successful like you submit a jar file.
Note: You do not need to install Databricks spark-sklearn package too.
All things done on a single client node, is that clear? No distibuted install, no spark-sklearn or other additional libraries. Just do it.
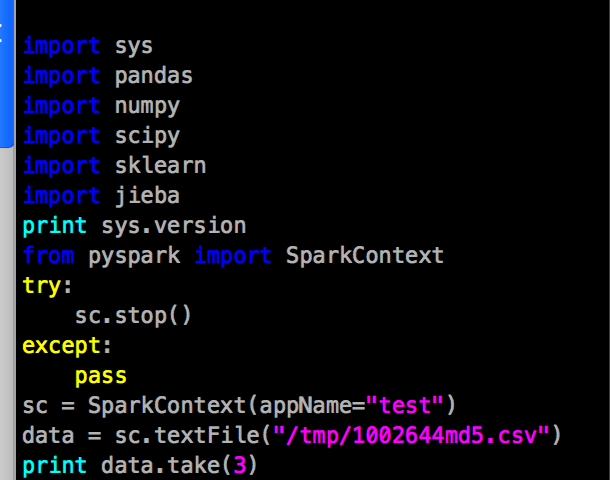
This is a test example I wrote firstly. uses spark, but just import sklearn, not use it. This code is running successfully either. “/tmp/xxxx.csv” was stored in HDFS, not a local file.