
We’ve updated Zeppelin from 0.7.0 to 0.7.1, still work with kerberized hadoop cluster, we use some interpreters in zeppelin, not all. And I wanna write some troubleshooting records with this awesome webtool. BTW: I can write a webtool better than this 1000 times, such as phpHiveAdmin, basically I can see the map/reduce prograss bar
We used
1. pyspark with python machine learning libraries
Since we use centos6 which using python 2.6, not support with python machine learning libraries, such as numpy, scipy, sklearn, pandas… So I had to compile new python 2.7 on each node, and pip install these libs. When I write a test demo in Zeppelin, it shows me an python error
#python import pandas import scipy import numpy import sklearn
It gives me this.
Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'list' object has no attribute 'show' Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'list' object has no attribute '_displayhook'
Well , this error means you forgot to install matplotlib, you should pip install it , and it will be fine.
2. Hive with new user
java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:279) at org.apache.commons.dbcp2.DelegatingStatement.execute(DelegatingStatement.java:291) at org.apache.commons.dbcp2.DelegatingStatement.execute(DelegatingStatement.java:291) at org.apache.zeppelin.jdbc.JDBCInterpreter.executeSql(JDBCInterpreter.java:580) at org.apache.zeppelin.jdbc.JDBCInterpreter.interpret(JDBCInterpreter.java:692) at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:95) at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:490) at org.apache.zeppelin.scheduler.Job.run(Job.java:175) at org.apache.zeppelin.scheduler.ParallelScheduler$JobRunner.run(ParallelScheduler.java:162) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745)
Well there are three parts will cause this issue.
first: You only added a zeppelin user, did not add this linux user to all of you hadoop nodes, zeppelin will use real username to submit a job to kerberized hadoop yarn instead using zeppelin user, unless, you set hadoop.proxy.zzeppelin.hosts and hadoop.proxy.zeppelin.group in core-site.xml
second: You did not added this kerberos username with kadmin.
third: You did not create this user’s home directory on HDFS.
Check these 3 parts, it should be ok.
And another thing is, you should put hive-site.xml in zeppelin’s conf dir.
3. Install R to work with Zeppelin
first: Install R to each node
yum -y install R R-devel libcurl-devel openssl-devel (install epel previously of course)
second: Install R packages
install.packages(c('devtools', 'knitr', 'ggplot2', 'mplot', 'googleVis', 'glmnet', 'pROC', 'data.table', 'rJava', 'stringi', 'stringr', 'evaluate', 'reshape2', 'caret', 'sqldf', 'wordcloud'), repos='https://mirrors.tuna.tsinghua.edu.cn/CRAN')
third: compile zeppelin with this options below, because of R uses GPL license, so mvn will not compile Zeppelin with SparkR support by default. You must add -Pr and -Psparkr arguments and rerun maven package.
mvn package ......
-Pspark-1.6 -Dspark.version=$SPARK_VERSION \
-Phadoop-2.6 -Dhadoop.version=$HADOOP_VERSION \
-Pyarn \
-Pr \
-Psparkr \
-Pscala-2.10 \
-Pbuild-distr"
And then, next error:
library(‘SparkR’) not found
devtools::install_github("amplab-extras/SparkR-pkg", subdir="pkg")
4. Write HiveQL in %spark.pyspark
such like this:
from pyspark.sql import HiveContext, Row newHiveContext=HiveContext(sc) query1="""select * from track.click limit 100""" rows1=newHiveContext.sql(query1) rows1.show()
In cli, it’s ok, but in Zeppelin, it will cause an exception below:
Traceback (most recent call last):
File "/tmp/zeppelin_pyspark-5311749997581805313.py", line 349, in <module>
raise Exception(traceback.format_exc())
Exception: Traceback (most recent call last):
File "/tmp/zeppelin_pyspark-5311749997581805313.py", line 342, in <module>
exec(code)
File "<stdin>", line 5, in <module>
File "/usr/lib/spark/python/pyspark/sql/dataframe.py", line 257, in show
print(self._jdf.showString(n, truncate))
File "/usr/lib/spark/python/lib/py4j-0.9-src.zip/py4j/java_gateway.py", line 813, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "/usr/lib/spark/python/pyspark/sql/utils.py", line 45, in deco
return f(*a, **kw)
File "/usr/lib/spark/python/lib/py4j-0.9-src.zip/py4j/protocol.py", line 308, in get_return_value
format(target_id, ".", name), value)
Py4JJavaError: An error occurred while calling o47.showString.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, pg-dmp-slave7.hadoop, executor 1): java.lang.NoClassDefFoundError: Lorg/apache/hadoop/hive/ql/plan/TableDesc;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2436)
at java.lang.Class.getDeclaredField(Class.java:1946)
at java.io.ObjectStreamClass.getDeclaredSUID(ObjectStreamClass.java:1659)
at java.io.ObjectStreamClass.access$700(ObjectStreamClass.java:72)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:480)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:468)
at java.security.AccessController.doPrivileged(Native Method)
at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:468)
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:365)
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:602)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1622)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1517)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1771)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at scala.collection.immutable.$colon$colon.readObject(List.scala:362)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1017)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1893)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at scala.collection.immutable.$colon$colon.readObject(List.scala:362)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1017)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1893)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readArray(ObjectInputStream.java:1706)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1344)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at scala.collection.immutable.$colon$colon.readObject(List.scala:362)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1017)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1893)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:76)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:115)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:61)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:229)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.ql.plan.TableDesc
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
... 104 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1431)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1419)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1418)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1418)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:799)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:799)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:799)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1642)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1601)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1590)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:620)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1844)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1857)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1870)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:212)
at org.apache.spark.sql.execution.Limit.executeCollect(basicOperators.scala:165)
at org.apache.spark.sql.execution.SparkPlan.executeCollectPublic(SparkPlan.scala:174)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:53)
at org.apache.spark.sql.DataFrame.withNewExecutionId(DataFrame.scala:2086)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$execute$1(DataFrame.scala:1498)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$collect(DataFrame.scala:1505)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1375)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.withCallback(DataFrame.scala:2099)
at org.apache.spark.sql.DataFrame.head(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.take(DataFrame.scala:1456)
at org.apache.spark.sql.DataFrame.showString(DataFrame.scala:170)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:231)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:381)
at py4j.Gateway.invoke(Gateway.java:259)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:133)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:209)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.NoClassDefFoundError: Lorg/apache/hadoop/hive/ql/plan/TableDesc;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2436)
at java.lang.Class.getDeclaredField(Class.java:1946)
at java.io.ObjectStreamClass.getDeclaredSUID(ObjectStreamClass.java:1659)
at java.io.ObjectStreamClass.access$700(ObjectStreamClass.java:72)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:480)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:468)
at java.security.AccessController.doPrivileged(Native Method)
at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:468)
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:365)
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:602)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1622)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1517)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1771)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at scala.collection.immutable.$colon$colon.readObject(List.scala:362)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1017)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1893)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at scala.collection.immutable.$colon$colon.readObject(List.scala:362)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1017)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1893)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readArray(ObjectInputStream.java:1706)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1344)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at scala.collection.immutable.$colon$colon.readObject(List.scala:362)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1017)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1893)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:76)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:115)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:61)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:229)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
... 1 more
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.ql.plan.TableDesc
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
... 104 more
/usr/lib/hive/lib/hive-jdbc-1.1.0-cdh5.9.0.jar
/usr/lib/hadoop/hadoop-common-2.6.0-cdh5.9.0.jar
/usr/lib/hive/lib/hive-jdbc-1.1.0-cdh5.9.0-standalone.jar
/usr/lib/hive/lib/hive-shims-0.23-1.1.0-cdh5.9.0.jar
/usr/lib/hadoop/hadoop-auth-2.6.0-cdh5.9.0.jar
add these jars into spark conf->depends area in zeppelin interpreters config page.
5. I used to compile zeppelin without R, and I re-compile zeppelin with R, and set it in interpreters page, but it still not work
Well, actually, I confused with this for a day, until I realized, Zeppelin’s notes or paragraphs are all bound to interpreters, so even you change the zeppelin, it still work with old interpreters. So it seems you must delete your whole note and rewrite a new one. I think this is a ridiculous architecture design
6. Cannot use SQL DataFrame Context in pyspark in Zeppelin / Cannot verify credential exception / Spark application hangs up, cannot be finished in YARN app manager.
Well, these three question seems to be one problem.
sqlContext.registerDataFrameAsTable(content_df, 'content_df')
select * from content_df where packageName='com.qiyi.video' limit 100
INFO [2017-05-26 13:43:30,079] ({pool-2-thread-18} SchedulerFactory.java[jobStarted]:131) - Job remoteInterpretJob_1495777410079 started by scheduler org.apache.zeppelin.spark.SparkSqlInterpreter514869690
ERROR [2017-05-26 13:43:30,081] ({pool-2-thread-18} Job.java[run]:188) - Job failed
org.apache.zeppelin.interpreter.InterpreterException: java.lang.reflect.InvocationTargetException
at org.apache.zeppelin.spark.SparkSqlInterpreter.interpret(SparkSqlInterpreter.java:119)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:95)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:490)
at org.apache.zeppelin.scheduler.Job.run(Job.java:175)
at org.apache.zeppelin.scheduler.ParallelScheduler$JobRunner.run(ParallelScheduler.java:162)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.zeppelin.spark.SparkSqlInterpreter.interpret(SparkSqlInterpreter.java:116)
... 11 more
Caused by: java.lang.NullPointerException
at org.apache.spark.sql.hive.client.ClientWrapper.conf(ClientWrapper.scala:205)
at org.apache.spark.sql.hive.HiveContext.hiveconf$lzycompute(HiveContext.scala:554)
at org.apache.spark.sql.hive.HiveContext.hiveconf(HiveContext.scala:553)
at org.apache.spark.sql.hive.HiveContext.parseSql(HiveContext.scala:333)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:817)
... 16 more
ERROR [2017-05-26 13:47:16,017] ({pool-2-thread-2} Logging.scala[logError]:95) - Uncaught exception in thread pool-2-thread-2
java.lang.StackOverflowError
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater.updateCredentialsIfRequired(ExecutorDelegationTokenUpdater.scala:89)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply$mcV$sp(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1766)
......
WARN [2017-05-26 13:47:16,035] ({pool-2-thread-2} Logging.scala[logWarning]:91) - Error while trying to update credentials, will try again in 1 hour
java.lang.StackOverflowError
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater.updateCredentialsIfRequired(ExecutorDelegationTokenUpdater.scala:89)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply$mcV$sp(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1766)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1.run(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater.updateCredentialsIfRequired(ExecutorDelegationTokenUpdater.scala:79)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply$mcV$sp(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply(ExecutorDelegationTokenUpdater.scala:49)
at org.apache.spark.deploy.yarn.ExecutorDelegationTokenUpdater$$anon$1$$anonfun$run$1.apply(ExecutorDelegationTokenUpdater.scala:49)
I found this error in zeppelin/spark/src/main/org/apache/zeppelin/spark/SparkSqlInterpreter.java
public InterpreterResult interpret(String st, InterpreterContext context) {
SQLContext sqlc = null;
SparkInterpreter sparkInterpreter = getSparkInterpreter();
if (sparkInterpreter.getSparkVersion().isUnsupportedVersion()) {
return new InterpreterResult(Code.ERROR, "Spark "
+ sparkInterpreter.getSparkVersion().toString() + " is not supported");
}
sparkInterpreter.populateSparkWebUrl(context);
sqlc = getSparkInterpreter().getSQLContext();
SparkContext sc = sqlc.sparkContext();
if (concurrentSQL()) {
sc.setLocalProperty("spark.scheduler.pool", "fair");
} else {
sc.setLocalProperty("spark.scheduler.pool", null);
}
sc.setJobGroup(getJobGroup(context), "Zeppelin", false);
Object rdd = null;
try {
// method signature of sqlc.sql() is changed
// from def sql(sqlText: String): SchemaRDD (1.2 and prior)
// to def sql(sqlText: String): DataFrame (1.3 and later).
// Therefore need to use reflection to keep binary compatibility for all spark versions.
Method sqlMethod = sqlc.getClass().getMethod("sql", String.class);
rdd = sqlMethod.invoke(sqlc, st);
} <span style="color: #ff0000;" data-mce-style="color: #ff0000;">catch (InvocationTargetException ite) {
if (Boolean.parseBoolean(getProperty("zeppelin.spark.sql.stacktrace"))) {
throw new InterpreterException(ite);
}
logger.error("Invocation target exception", ite);
String msg = ite.getTargetException().getMessage()
+ "\nset zeppelin.spark.sql.stacktrace = true to see full stacktrace";
return new InterpreterResult(Code.ERROR, msg);</span>
} catch (NoSuchMethodException | SecurityException | IllegalAccessException
| IllegalArgumentException e) {
throw new InterpreterException(e);
}
String msg = ZeppelinContext.showDF(sc, context, rdd, maxResult);
sc.clearJobGroup();
return new InterpreterResult(Code.SUCCESS, msg);
}
If you enable HiveContext in zeppelin.spark.config, it cannot read schema that you registered in DataFrameAsTable, and it will try to use hive’s keytab to instead zeppelin keytab, and then, hangs up in YARN app manager.
To resolve this, just set
zeppelin.spark.useHiveContext = false
In zeppelin’s interpreter config page.
Well, gives you my interpreters configs that I used:
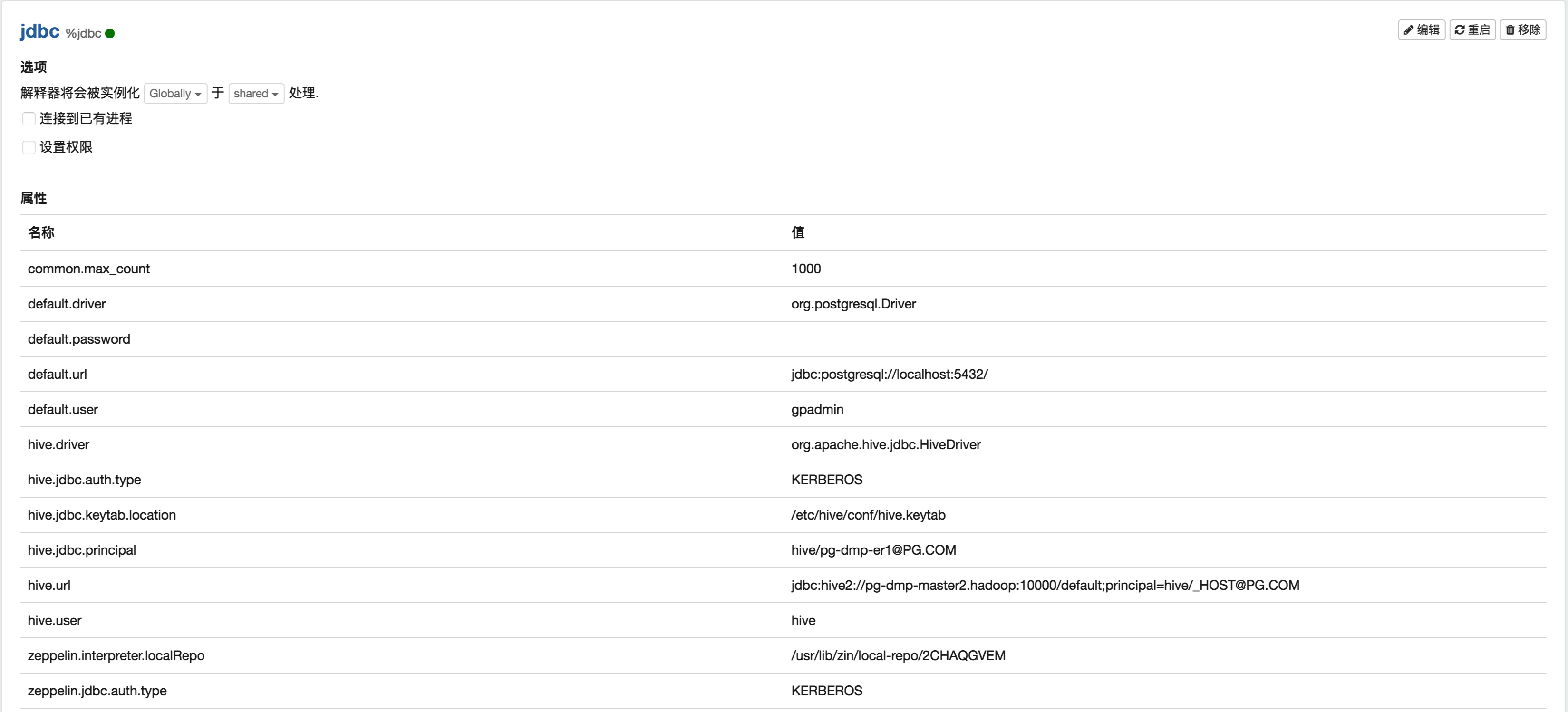
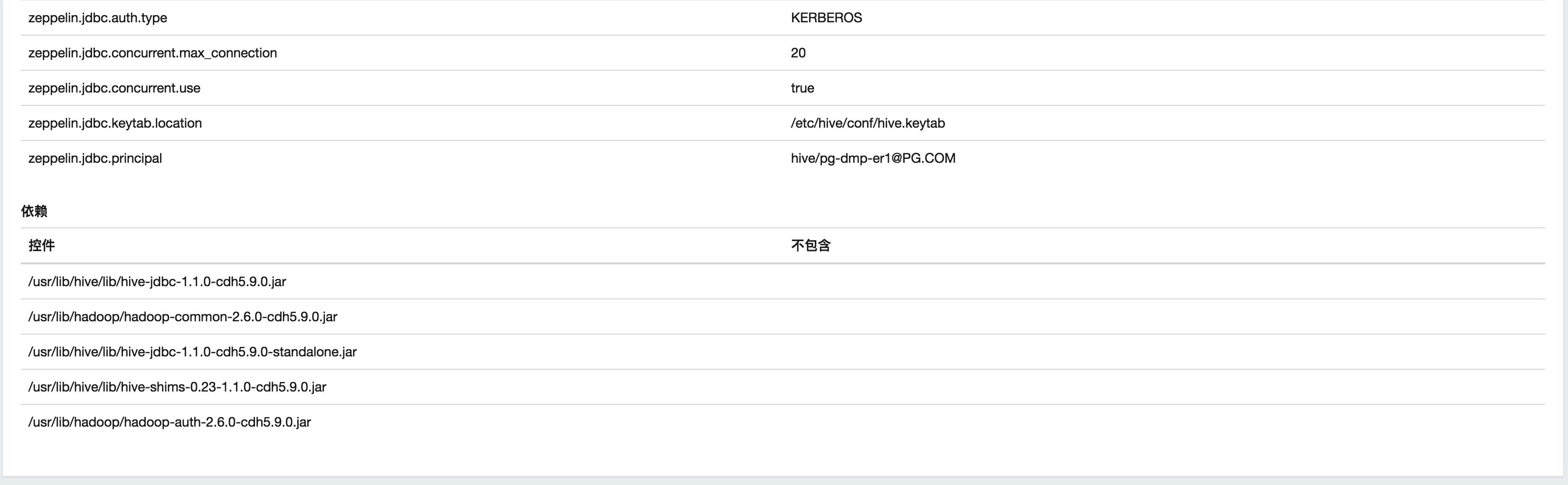
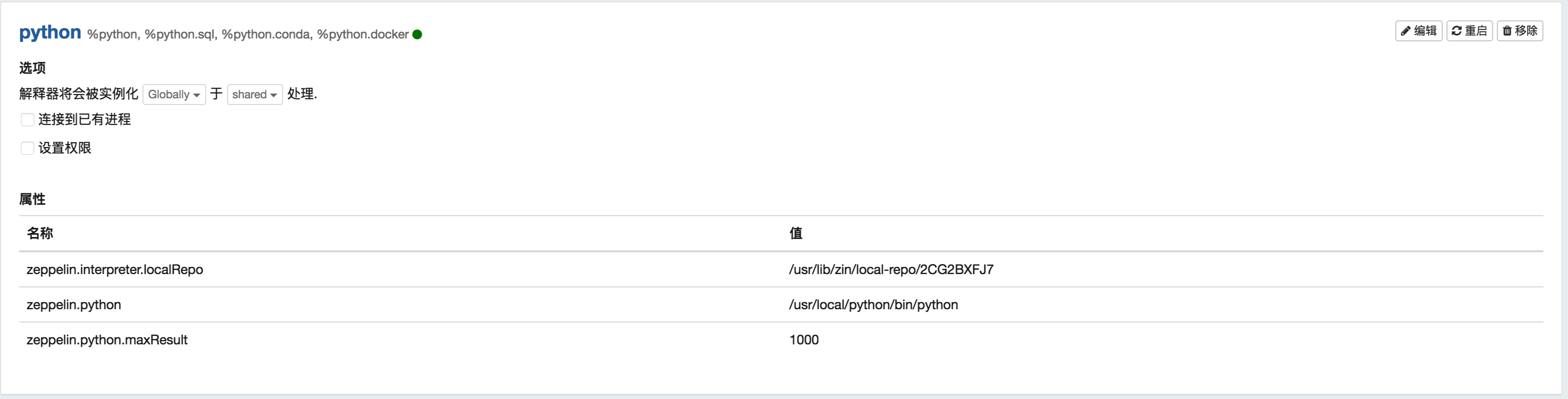
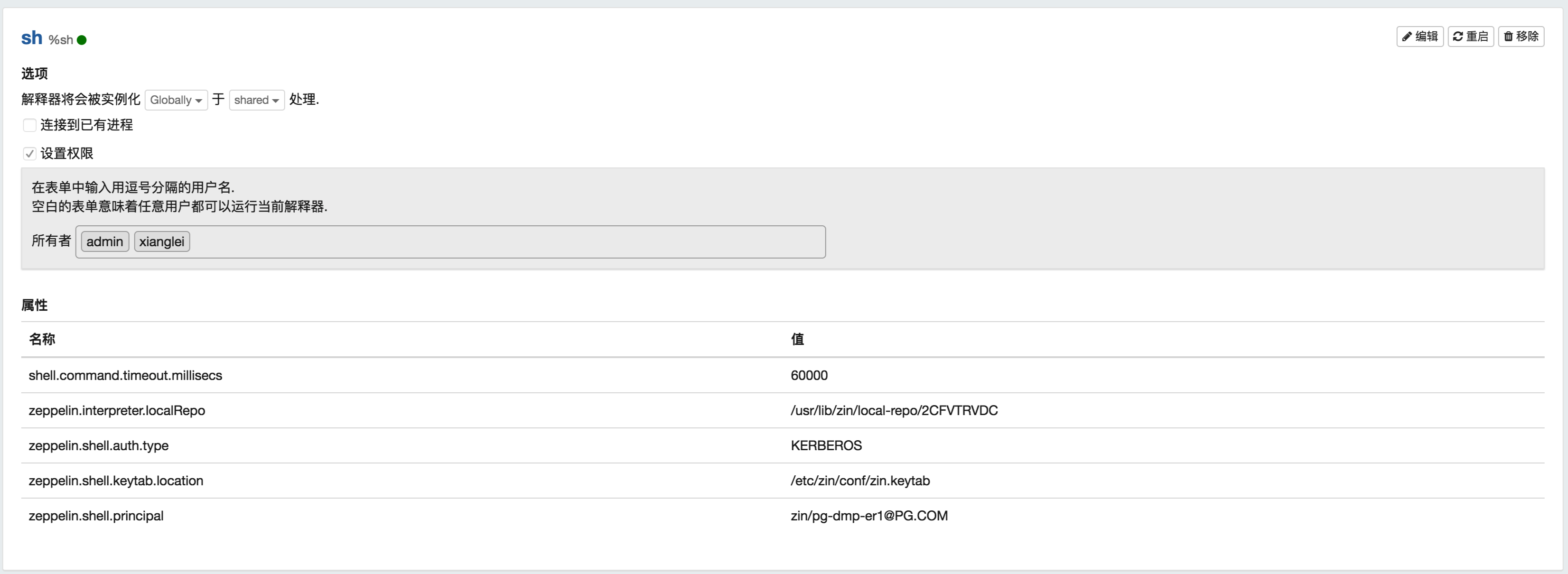
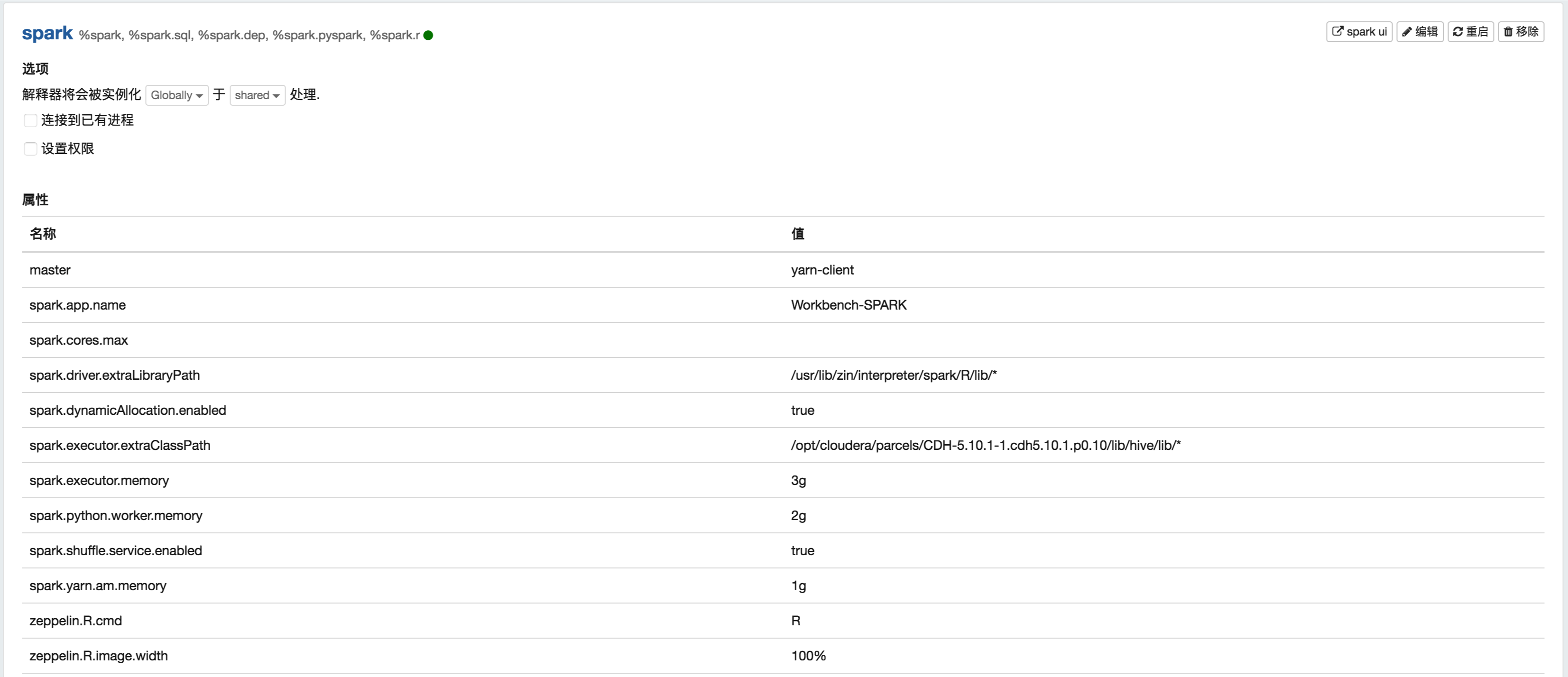


My Zeppelin configurations and for debugging arguments:
zeppelin-env.sh
export ZEPPELIN_INTERPRETERS="org.apache.zeppelin.spark.SparkInterpreter,org.apache.zeppelin.spark.PySparkInterpreter,org.apache.zeppelin.spark.SparkSqlInterpreter,org.apache.zeppelin.spark.DepInterpreter,org.apache.zeppelin.markdown.Markdown,org.apache.zeppelin.angular.AngularInterpreter,org.apache.zeppelin.shell.ShellInterpreter,org.apache.zeppelin.hive.HiveInterpreter" export ZEPPELIN_PORT=8080 export ZEPPELIN_CONF_DIR=/etc/zin/conf export ZEPPELIN_LOG_DIR=/var/log/zin export ZEPPELIN_PID_DIR=/var/run/zin export ZEPPELIN_WAR_TEMPDIR=/var/run/zin/webapps export ZEPPELIN_NOTEBOOK_DIR=/var/lib/zin/notebook export MASTER=yarn-client export SPARK_HOME=/usr/lib/spark export HADOOP_CONF_DIR=/etc/hadoop/conf:/etc/hive/conf export ZEPPELIN_JAVA_OPTS="-Dspark.yarn.jar=/usr/lib/zin/interpreter/spark/zeppelin-spark_2.10-0.7.1.jar" export HADOOP_HOME=/usr/lib/hadoop export ZEPPELIN_INTP_CLASSPATH_OVERRIDES=/etc/hive/conf export ZEPPELIN_HOME=/usr/lib/zin #add this line for debugging export SPARK_PRINT_LAUNCH_COMMAND=true
log4j.properties
log4j.rootLogger = INFO, dailyfile
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%d] ({%t} %F[%M]:%L) - %m%n
log4j.appender.dailyfile.DatePattern=.yyyy-MM-dd
log4j.appender.dailyfile.Threshold = DEBUG
log4j.appender.dailyfile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.dailyfile.File = ${zeppelin.log.file}
log4j.appender.dailyfile.layout = org.apache.log4j.PatternLayout
log4j.appender.dailyfile.layout.ConversionPattern=%5p [%d] ({%t} %F[%M]:%L) - %m%n
#add these lines for debugging
log4j.logger.org.apache.zeppelin.interpreter.InterpreterFactory=DEBUG
log4j.logger.org.apache.zeppelin.notebook.Paragraph=DEBUG
log4j.logger.org.apache.zeppelin.scheduler=DEBUG
log4j.logger.org.apache.zeppelin.livy=DEBUG
log4j.logger.org.apache.zeppelin.flink=DEBUG
log4j.logger.org.apache.zeppelin.spark=DEBUG
log4j.logger.org.apache.zeppelin.interpreter.util=DEBUG
log4j.logger.org.apache.zeppelin.interpreter.remote=DEBUG
zeppelin-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>8080</value>
<description>Server port.</description>
</property>
<property>
<name>zeppelin.server.ssl.port</name>
<value>8443</value>
<description>Server ssl port. (used when ssl property is set to true)</description>
</property>
<property>
<name>zeppelin.server.context.path</name>
<value>/</value>
<description>Context Path of the Web Application</description>
</property>
<property>
<name>zeppelin.war.tempdir</name>
<value>webapps</value>
<description>Location of jetty temporary directory</description>
</property>
<property>
<name>zeppelin.notebook.dir</name>
<value>notebook</value>
<description>path or URI for notebook persist</description>
</property>
<property>
<name>zeppelin.notebook.homescreen</name>
<value></value>
<description>id of notebook to be displayed in homescreen. ex) 2A94M5J1Z Empty value displays default home screen</description>
</property>
<property>
<name>zeppelin.notebook.homescreen.hide</name>
<value>false</value>
<description>hide homescreen notebook from list when this value set to true</description>
</property>
<!-- Amazon S3 notebook storage -->
<!-- Creates the following directory structure: s3://{bucket}/{username}/{notebook-id}/note.json -->
<!--
<property>
<name>zeppelin.notebook.s3.user</name>
<value>user</value>
<description>user name for s3 folder structure</description>
</property>
<property>
<name>zeppelin.notebook.s3.bucket</name>
<value>zeppelin</value>
<description>bucket name for notebook storage</description>
</property>
<property>
<name>zeppelin.notebook.s3.endpoint</name>
<value>s3.amazonaws.com</value>
<description>endpoint for s3 bucket</description>
</property>
<property>
<name>zeppelin.notebook.storage</name>
<value>org.apache.zeppelin.notebook.repo.S3NotebookRepo</value>
<description>notebook persistence layer implementation</description>
</property>
-->
<!-- Additionally, encryption is supported for notebook data stored in S3 -->
<!-- Use the AWS KMS to encrypt data -->
<!-- If used, the EC2 role assigned to the EMR cluster must have rights to use the given key -->
<!-- See https://aws.amazon.com/kms/ and http://docs.aws.amazon.com/kms/latest/developerguide/concepts.html -->
<!--
<property>
<name>zeppelin.notebook.s3.kmsKeyID</name>
<value>AWS-KMS-Key-UUID</value>
<description>AWS KMS key ID used to encrypt notebook data in S3</description>
</property>
-->
<!-- provide region of your KMS key -->
<!-- See http://docs.aws.amazon.com/general/latest/gr/rande.html#kms_region for region codes names -->
<!--
<property>
<name>zeppelin.notebook.s3.kmsKeyRegion</name>
<value>us-east-1</value>
<description>AWS KMS key region in your AWS account</description>
</property>
-->
<!-- Use a custom encryption materials provider to encrypt data -->
<!-- No configuration is given to the provider, so you must use system properties or another means to configure -->
<!-- See https://docs.aws.amazon.com/AWSJavaSDK/latest/javadoc/com/amazonaws/services/s3/model/EncryptionMaterialsProvider.html -->
<!--
<property>
<name>zeppelin.notebook.s3.encryptionMaterialsProvider</name>
<value>provider implementation class name</value>
<description>Custom encryption materials provider used to encrypt notebook data in S3</description>
</property>
-->
<!-- If using Azure for storage use the following settings -->
<!--
<property>
<name>zeppelin.notebook.azure.connectionString</name>
<value>DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey></value>
<description>Azure account credentials</description>
</property>
<property>
<name>zeppelin.notebook.azure.share</name>
<value>zeppelin</value>
<description>share name for notebook storage</description>
</property>
<property>
<name>zeppelin.notebook.azure.user</name>
<value>user</value>
<description>optional user name for Azure folder structure</description>
</property>
<property>
<name>zeppelin.notebook.storage</name>
<value>org.apache.zeppelin.notebook.repo.AzureNotebookRepo</value>
<description>notebook persistence layer implementation</description>
</property>
-->
<!-- Notebook storage layer using local file system
<property>
<name>zeppelin.notebook.storage</name>
<value>org.apache.zeppelin.notebook.repo.VFSNotebookRepo</value>
<description>local notebook persistence layer implementation</description>
</property>
-->
<!-- For connecting your Zeppelin with ZeppelinHub -->
<!--
<property>
<name>zeppelin.notebook.storage</name>
<value>org.apache.zeppelin.notebook.repo.GitNotebookRepo, org.apache.zeppelin.notebook.repo.zeppelinhub.ZeppelinHubRepo</value>
<description>two notebook persistence layers (versioned local + ZeppelinHub)</description>
</property>
-->
<property>
<name>zeppelin.notebook.storage</name>
<value>org.apache.zeppelin.notebook.repo.GitNotebookRepo</value>
<description>versioned notebook persistence layer implementation</description>
</property>
<property>
<name>zeppelin.notebook.one.way.sync</name>
<value>false</value>
<description>If there are multiple notebook storages, should we treat the first one as the only source of truth?</description>
</property>
<property>
<name>zeppelin.interpreter.dir</name>
<value>interpreter</value>
<description>Interpreter implementation base directory</description>
</property>
<property>
<name>zeppelin.interpreter.localRepo</name>
<value>local-repo</value>
<description>Local repository for interpreter's additional dependency loading</description>
</property>
<property>
<name>zeppelin.interpreters</name>
<value>org.apache.zeppelin.spark.SparkInterpreter,org.apache.zeppelin.spark.PySparkInterpreter,org.apache.zeppelin.rinterpreter.RRepl,org.apache.zeppelin.rinterpreter.KnitR,org.apache.zeppelin.spark.SparkRInterpreter,org.apache.zeppelin.spark.SparkSqlInterpreter,org.apache.zeppelin.spark.DepInterpreter,org.apache.zeppelin.markdown.Markdown,org.apache.zeppelin.angular.AngularInterpreter,org.apache.zeppelin.shell.ShellInterpreter,org.apache.zeppelin.file.HDFSFileInterpreter,org.apache.zeppelin.flink.FlinkInterpreter,,org.apache.zeppelin.python.PythonInterpreter,org.apache.zeppelin.python.PythonInterpreterPandasSql,org.apache.zeppelin.python.PythonCondaInterpreter,org.apache.zeppelin.python.PythonDockerInterpreter,org.apache.zeppelin.lens.LensInterpreter,org.apache.zeppelin.ignite.IgniteInterpreter,org.apache.zeppelin.ignite.IgniteSqlInterpreter,org.apache.zeppelin.cassandra.CassandraInterpreter,org.apache.zeppelin.geode.GeodeOqlInterpreter,org.apache.zeppelin.postgresql.PostgreSqlInterpreter,org.apache.zeppelin.jdbc.JDBCInterpreter,org.apache.zeppelin.kylin.KylinInterpreter,org.apache.zeppelin.elasticsearch.ElasticsearchInterpreter,org.apache.zeppelin.scalding.ScaldingInterpreter,org.apache.zeppelin.alluxio.AlluxioInterpreter,org.apache.zeppelin.hbase.HbaseInterpreter,org.apache.zeppelin.livy.LivySparkInterpreter,org.apache.zeppelin.livy.LivyPySparkInterpreter,org.apache.zeppelin.livy.LivyPySpark3Interpreter,org.apache.zeppelin.livy.LivySparkRInterpreter,org.apache.zeppelin.livy.LivySparkSQLInterpreter,org.apache.zeppelin.bigquery.BigQueryInterpreter,org.apache.zeppelin.beam.BeamInterpreter,org.apache.zeppelin.pig.PigInterpreter,org.apache.zeppelin.pig.PigQueryInterpreter,org.apache.zeppelin.scio.ScioInterpreter</value>
<description>Comma separated interpreter configurations. First interpreter become a default</description>
</property>
<property>
<name>zeppelin.interpreter.group.order</name>
<value>spark,md,angular,sh,livy,alluxio,file,psql,flink,python,ignite,lens,cassandra,geode,kylin,elasticsearch,scalding,jdbc,hbase,bigquery,beam</value>
<description></description>
</property>
<property>
<name>zeppelin.interpreter.connect.timeout</name>
<value>30000</value>
<description>Interpreter process connect timeout in msec.</description>
</property>
<property>
<name>zeppelin.ssl</name>
<value>false</value>
<description>Should SSL be used by the servers?</description>
</property>
<property>
<name>zeppelin.ssl.client.auth</name>
<value>false</value>
<description>Should client authentication be used for SSL connections?</description>
</property>
<property>
<name>zeppelin.ssl.keystore.path</name>
<value>keystore</value>
<description>Path to keystore relative to Zeppelin configuration directory</description>
</property>
<property>
<name>zeppelin.ssl.keystore.type</name>
<value>JKS</value>
<description>The format of the given keystore (e.g. JKS or PKCS12)</description>
</property>
<property>
<name>zeppelin.ssl.keystore.password</name>
<value>change me</value>
<description>Keystore password. Can be obfuscated by the Jetty Password tool</description>
</property>
<!--
<property>
<name>zeppelin.ssl.key.manager.password</name>
<value>change me</value>
<description>Key Manager password. Defaults to keystore password. Can be obfuscated.</description>
</property>
-->
<property>
<name>zeppelin.ssl.truststore.path</name>
<value>truststore</value>
<description>Path to truststore relative to Zeppelin configuration directory. Defaults to the keystore path</description>
</property>
<property>
<name>zeppelin.ssl.truststore.type</name>
<value>JKS</value>
<description>The format of the given truststore (e.g. JKS or PKCS12). Defaults to the same type as the keystore type</description>
</property>
<!--
<property>
<name>zeppelin.ssl.truststore.password</name>
<value>change me</value>
<description>Truststore password. Can be obfuscated by the Jetty Password tool. Defaults to the keystore password</description>
</property>
-->
<property>
<name>zeppelin.server.allowed.origins</name>
<value>*</value>
<description>Allowed sources for REST and WebSocket requests (i.e. http://onehost:8080,http://otherhost.com). If you leave * you are vulnerable to https://issues.apache.org/jira/browse/ZEPPELIN-173</description>
</property>
<property>
<name>zeppelin.anonymous.allowed</name>
<value>false</value>
<description>Anonymous user allowed by default</description>
</property>
<property>
<name>zeppelin.notebook.public</name>
<value>false</value>
<description>Make notebook public by default when created, private otherwise</description>
</property>
<property>
<name>zeppelin.websocket.max.text.message.size</name>
<value>1024000</value>
<description>Size in characters of the maximum text message to be received by websocket. Defaults to 1024000</description>
</property>
</configuration>
No, I won’t paste shiro.ini here.