Due to our dear stingy Party A said they will add not any nodes to the cluster, so we must compress the data to reduce disk consumption. Actually I like LZ4, it’s natively supported by hadoop,[...]

Troubleshooting on Zeppelin with keberized cluster
We’ve updated Zeppelin from 0.7.0 to 0.7.1, still work with kerberized hadoop cluster, we use some interpreters in zeppelin, not all. And I wanna write some troubleshooting records with this awe[...]
Use kerberized Hive in Zeppelin
We deployed Apache Zeppelin 0.7.0 for the Kerberos secured Hadoop cluster, and my dear colleague cannot use it correctly, so I have to find out why he can’t use anything in Zeppelin, except shel[...]
Troubleshooting kerberized hive issues
Today, my colleagues want to use hive in zeppelin, it’s the first time to use hive in this new kerberized cluster, and unfortunately there was an authenticate issue of using hive. So I have to d[...]
Deploy shadowsocks
Since I live in China, the Great Fire Wall is almost blocked every thing on this planet, so I have to find lots of ladders to over the wall to find some useful things. Freegate, Lvdou, and shadow sock[...]

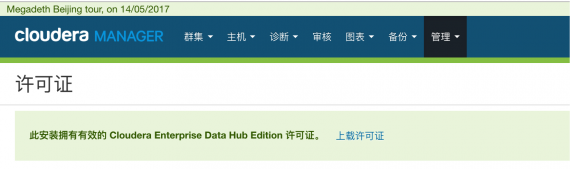
Enable Kerberos secured Hadoop cluster with Cloudera Manager
I created a secured Hadoop cluster for P&G with cloudera manager, and this document is to record how to enable kerberos secured cluster with cloudera manager. Firstly we should have a cluster that[...]

Dr.Elephant mysql connection error
This is the first time I try to use english to write my blog, so don’t jeer at the mistake of my grammar and spelling. Because of multi threaded drelephant will cause JobHistoryServer’s Lo[...]
试用时间序列数据库InfluxDB
Hadoop集群监控需要使用时间序列数据库,今天花了半天时间调研使用了一下最近比较火的InfluxDB,发现还真是不错,记录一下学习心得。 Influx是用Go语言写的,专为时间序列数据持久化所开发的,由于使用Go语言,所以各平台基本都支持。类似的时间序列数据库还有OpenTSDB,Prometheus等。 (更多…) [...]
Hadoop监控分析工具Dr.Elephant
公司基础架构这边想提取慢作业和获悉资源浪费的情况,所以装个dr elephant看看。LinkIn开源的系统,可以对基于yarn的mr和spark作业进行性能分析和调优建议。 DRE大部分基于java开发,spark监控部分使用scala开发,使用play堆栈式框架。这是一个类似Python里面Django的框架,基于java?scala?没太细了解,直接下来就能用,需要java1.8以上。 (更[...]